
Chaeyoung Jung
About Me
I am a second-year Ph.D. student at KAIST, advised by Professor Joon Son Chung. My research centers on multimodal learning, with a particular focus on deepening the understanding and reasoning capabilities of audio-visual large language models (AV-LLMs).
I am also passionate about generative modeling in audio, including text-to-audio generation, as well as speech-related tasks such as speech enhancement, source separation, and lip-to-speech synthesis.
Work Experience
- Research Intern at Meta Reality Lab, Burlingame, CA (2026.06 - 2026.11, Expected)
- Supervised by Zhaojiang Lin
Education
- Korea Advanced Institute of Science and Technology (KAIST), South Korea (2025 - Present)
- Ph.D in Electrical Engineering (advisor: Prof. Joon Son Chung)
- Korea Advanced Institute of Science and Technology (KAIST), South Korea (2023 - 2025)
- M.S in Electrical Engineering (advisor: Prof. Joon Son Chung)
- Korea Advanced Institute of Science and Technology (KAIST), South Korea (2018 - 2023)
- B.S in Electrical Engineering
News
- [Jan. 2026] One paper is accepted to ICASSP 2026.
- [Sep. 2025] One paper is accepted to NeurIPS 2025.
- [May. 2025] Two papers are accepted to Interspeech 2025.
- [Mar. 2025] I started Ph.D course in MMAI, KAIST!
Publications
-
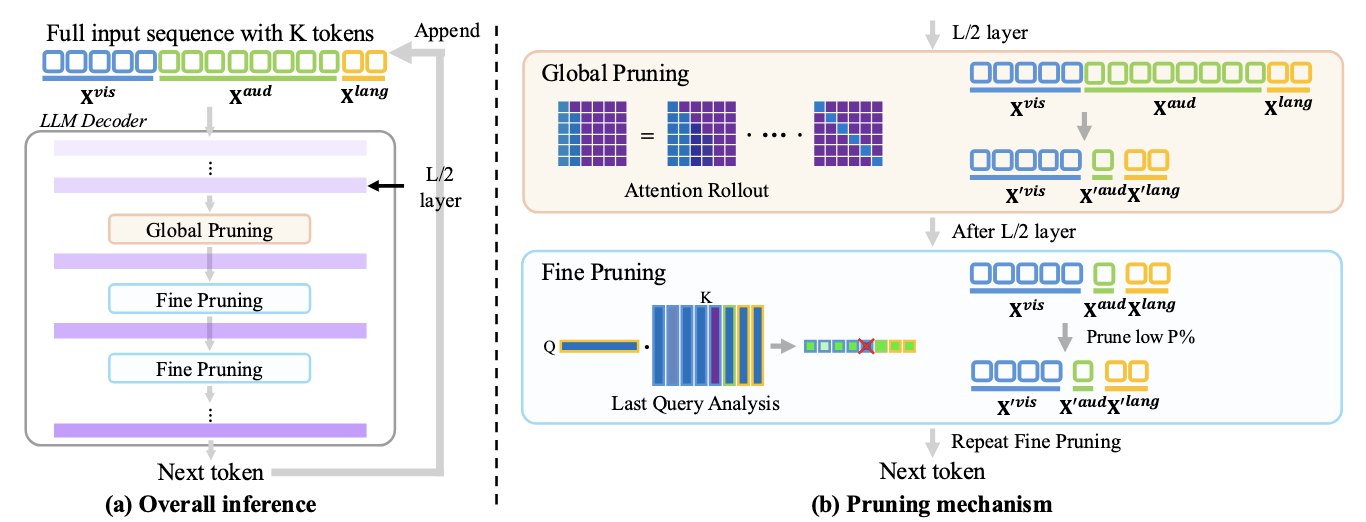 ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026.
ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026. -
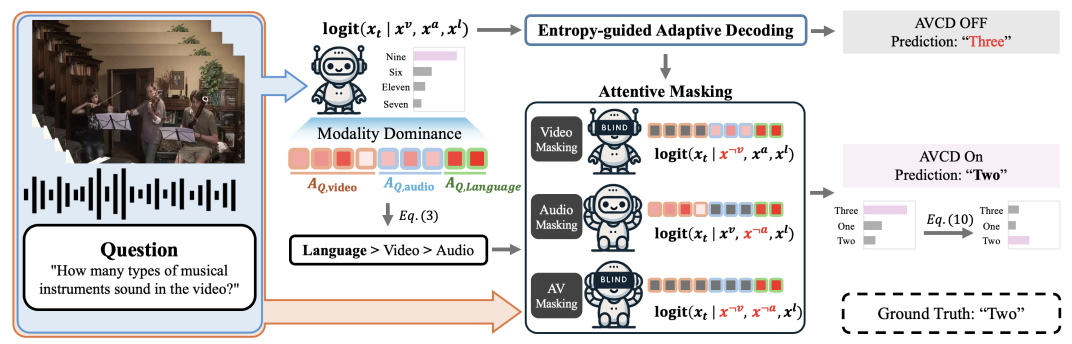 NeurIPS
Conference on Neural Information Processing Systems (NIPS), 2025.
NeurIPS
Conference on Neural Information Processing Systems (NIPS), 2025. -
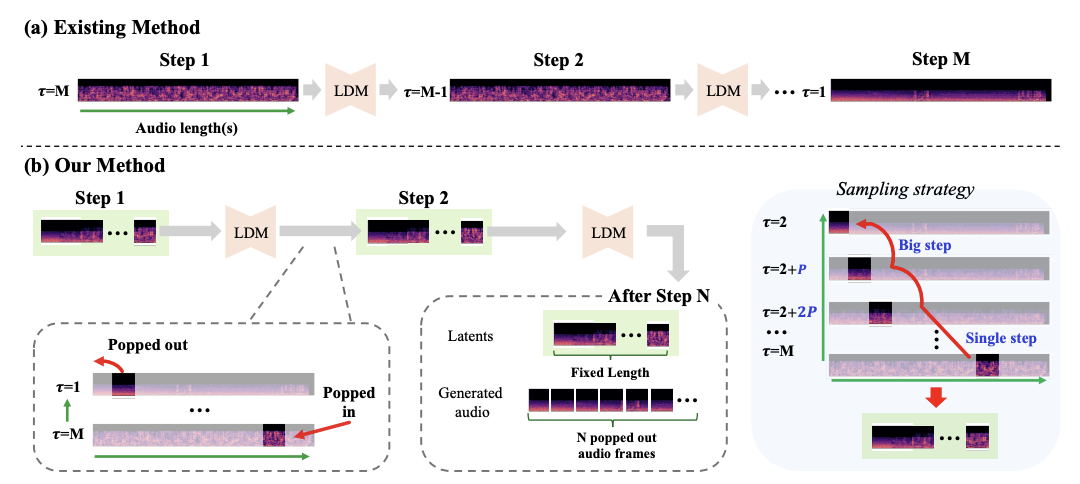 Interspeech
Conference of the International Speech Communication Association (Interspeech), 2025.PDF Oral
Interspeech
Conference of the International Speech Communication Association (Interspeech), 2025.PDF Oral -
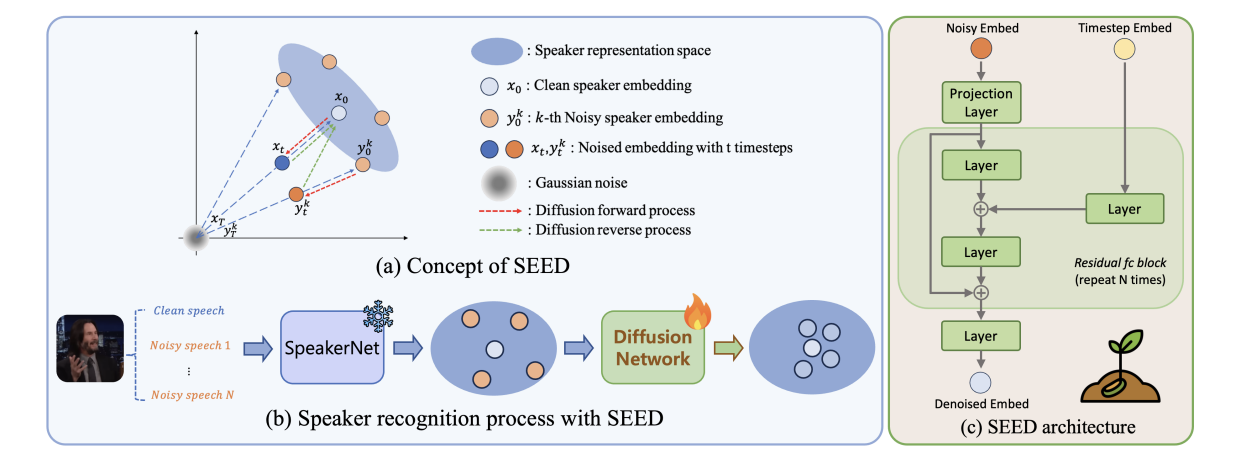 Interspeech
Conference of the International Speech Communication Association (Interspeech), 2025.
Interspeech
Conference of the International Speech Communication Association (Interspeech), 2025. -
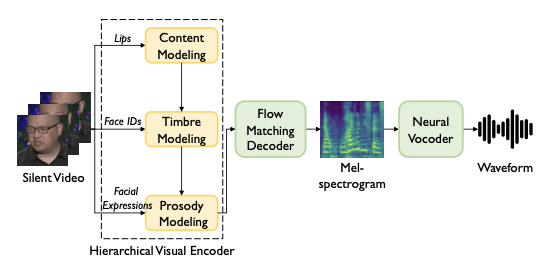 CVPR
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.PDF Highlight
CVPR
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.PDF Highlight -
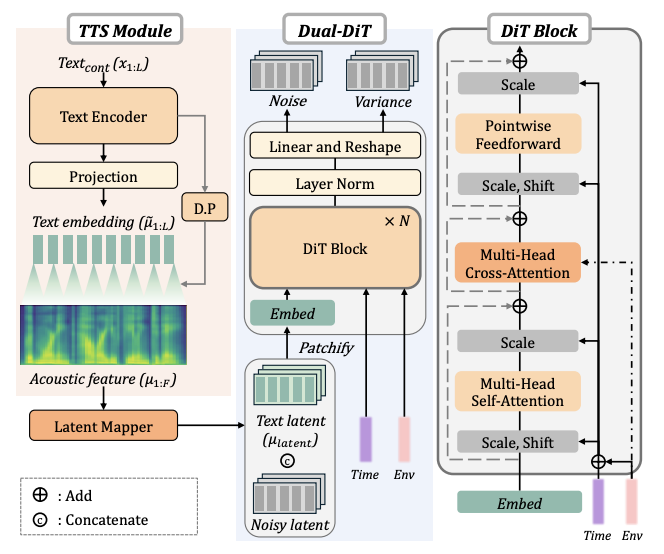 ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025.
ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025. -
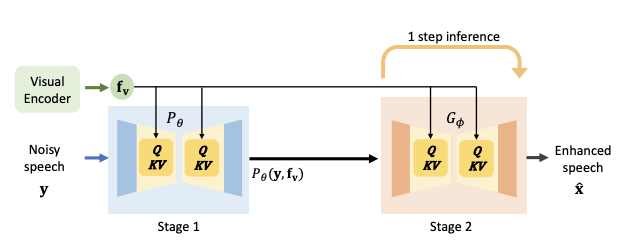 Interspeech
Conference of the International Speech Communication Association (Interspeech), 2024.
Interspeech
Conference of the International Speech Communication Association (Interspeech), 2024. -
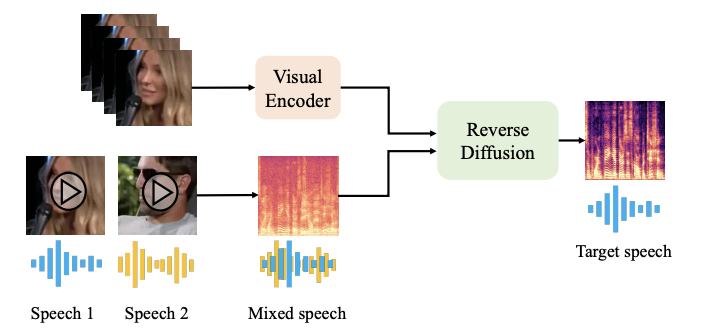 ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024. -
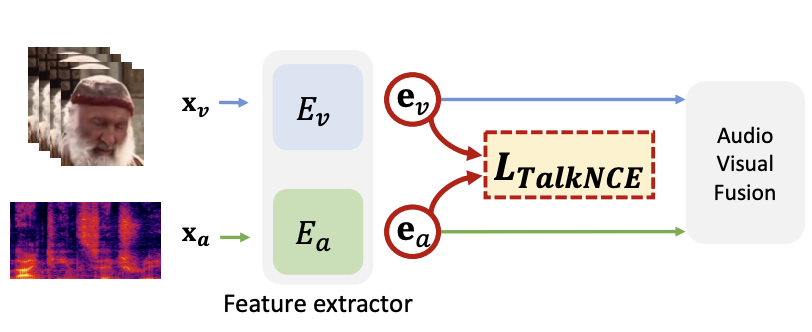 ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
ICASSP
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
Powered by Jekyll and Minimal Light theme.